

Dans le paysage dynamique de la data, un nouvel acteur a su se faire une place en occupant des niches stratégiques et en surpassant certains rivaux : DuckDB (site officiel – https://duckdb.org/). Il s’agit d’une base de données conçue pour les charges analytiques. Cette définition est peut-être trop simpliste, DuckDB, dont les usages sont multiples et variés, a été qualifié de couteau suisse de la data. Tous les métiers de la data peuvent tirer parti de ses capacités, que ce soit pour des analyses ad hoc, des traitements ETL, ou encore l’alimentation de tableaux de bord interactifs.
Polyvalence démontrée à travers plusieurs cas d’usage
Les capacités de DuckDB découlent de ses propriétés techniques. Voici quelques exemples illustrant sa flexibilité :
- Moteur analytique rapide et in-memory
Le logiciel peut être utilisé comme une base de données classique, intégré dans une application ou employé comme une bibliothèque. On peut l’utiliser dans des scripts, des notebooks Jupyter ou des applications pour alimenter des dashboards analytiques.
- SQL et API
Disposant d’un moteur SQL et d’une API, il est possible d’en interagir via une CLI, une interface graphique SQL ou un notebook. Les mêmes capacités du moteur SQL sont exposées via une API, avec des bindings disponibles pour plusieurs langages : Python, Java, Rust, etc.
- Lecture de formats variés
L’outil peut lire des fichiers aux formats CSV, JSON, Parquet, et interagir avec des datawarehouses de type Hive. Il permet ainsi des analyses interactives directement sur des fichiers stockés localement ou dans le cloud.
- Intégration dans des pipelines ETL
Grâce à son efficacité en termes de vitesse et de volume de traitement, il s’intègre facilement dans des workflows ETL.
- Connectivité BI
L’implémentation des protocoles JDBC, ODBC et ADBC, facilite la connexion avec des outils BI comme Power BI, Tableau, Superset, ou des applications web analytiques comme Streamlit, Dash ou Shiny.
Des workflows analytiques efficaces
DuckDB est un outil polyvalent pour une grande variété de workflows analytiques : analyse exploratoire (EDA), conversion rapide entre formats, création de pipelines complexes. Il permet d’importer de gros volumes de données hétérogènes, de nettoyer les données, de normaliser les schémas. Il s’intègre aux outils d’analyse courants (pandas, dashboards BI), permettant de combiner DuckDB avec d’autres outils afin de construire des workflows optimisés.
L’approche embarquée permet aux analystes et data scientists de traiter localement des fichiers volumineux avec rapidité, tout en conservant une syntaxe SQL familière.
L’interopérabilité avec des formats de données courants et des bibliothèques dataframes comme Pandas facilite son intégration dans des pipelines ETL ou des notebooks Jupyter. Par exemple, un analyste peut charger des datasets depuis le cloud ou depuis un repository interne, effectuer des jointures et des agrégations avec DuckDB, puis visualiser les résultats avec Plotly ou Seaborn. Une autre option pour explorer les résultats pourrait aboutir à une intégration dans des applications Streamlit pour créer des interfaces analytiques réactives. Cette fluidité permet de construire des workflows analytiques puissants sans quitter l’environnement local, tout en réduisant les temps de traitement et la complexité opérationnelle.
Un autre domaine où il excelle est celui des applications interactives : tableaux de bord BI, applications data-driven. Dans ces contextes, la rapidité de réponse et l’interactivité sont essentielles. Grâce à sa vitesse, c’est un excellent moteur analytique pour ces usages.
Intégration dans l’infrastructure data
L’outil s’intègre dans les architectures modernes, notamment pour les applications manipulant des volumes de données petits à moyenne taille, ou nécessitant une faible latence.
La majorité des organisations ne traitent pas des volumes massifs de données. Les jeux de données nettoyés et enrichis utilisés pour les décisions stratégiques (ventes, marketing, innovation produit) restent souvent bien en deçà du big data. Ce qui permet de s’affranchir des contraintes complexes pour aller vers des architectures plus simples et moins coûteuses.
Ceci dit, pour les cas où le volume des données est conséquent il y a une solution MotherDuck (https://motherduck.com/), qui est une fédération des instances DuckDB (l’outil lui-même est single node, pas une appli distribuée), solution orientée plutôt vers un usage datawarehouse.
Quant au déploiement, bien qu’initialement conçu pour un usage en local, DuckDB s’avère être cloud agnostique. Il n’y a pas de contrainte ou limitation pour un cloud ou une installation on premise, sur un serveur dédié ou un laptop. Dans un cloud on peut l’utiliser en serverless, avec une cloud function ou bien l’intégrer dans un workflow airflow/dagster.
Un moteur SQL analytique puissant et versatile
DuckDB offre un excellent support pour la création de requêtes SQL complexes, avec un accent particulier sur les fonctionnalités couramment utilisées dans les analyses de données. L’outil prend en charge les opérations d’agrégation et des jointures optimisées, les index de colonnes, les fonctions de fenêtrage et la recherche de texte. Il propose également un large éventail de fonctions pour manipuler différents types de données, notamment les opérations numériques, les opérations de date et d’heure, le
formatage des dates, les opérations de texte, du pattern matching, les expressions régulières. Les analyses de données sont encore facilitées par des commandes SQL telles que SAMPLE, qui permet un échantillonnage des jeux de données, et la commande PIVOT, qui permet de créer des tableaux croisés dynamiques.
La base propose également une large gamme de types de données, qui, outre les types classiques tels que les types numériques, de date et de texte, incluent des types pratiques comme INTERVAL pour les ranges, ENUM pour les énumérations et des types de données complexes, notamment ARRAY, LIST, STRUCT et MAP.
Le dialecte SQL de DuckDB est décrit sur le site officiel: https://duckdb.org/docs/guides/sql_features/friendly_sql
Cas d’usage client
Dans le cadre d’un projet mené au sein d’une banque d’investissement française, Starclay avait pour mission de construire un pipeline d’ingestion automatisé. Ce pipeline devait alimenter quotidiennement un datawarehouse avec les données de trading de la veille, issues de marchés régionaux, afin de répondre aux exigences de reporting réglementaire.
Si le pipeline fonctionnait correctement pour les données journalières (chaque fichier CSV chargé à la date D contenait les trades de la date D-1), une contrainte réglementaire imposait également l’intégration de données historiques remontant à quelques années. Or, nous disposions uniquement d’un dump dans un seul fichier CSV, avec un format différent, disponible dans un bucket S3.
Pour intégrer ces données historiques, nous avons d’abord chargé le fich
ier dans DuckDB via une table temporaire. Après une phase d’analyse, nous avons appliqué les transformations nécessaires pour adapter le format source au format cible du datawarehouse. Les données ont ensuite été segmentées par date, puis exportées en fichiers CSV individuels — un par jour de trading. Au total, environ un millier de fichiers ont été générés,
couvrant 3 à 4 années d’activité. La totalité des opérations ont été réalisées en SQL, directement dans le CLI de DuckDB (chargement depuis le cloud AWS, transformations des données, export en format csv). Bien que nous ayons utilisé le CLI, ce processus aurait pu être exécuté avec n’importe quel client SQL compatible DuckDB, comme Beekeeper Studio illustré dans le schéma ci-dessous.
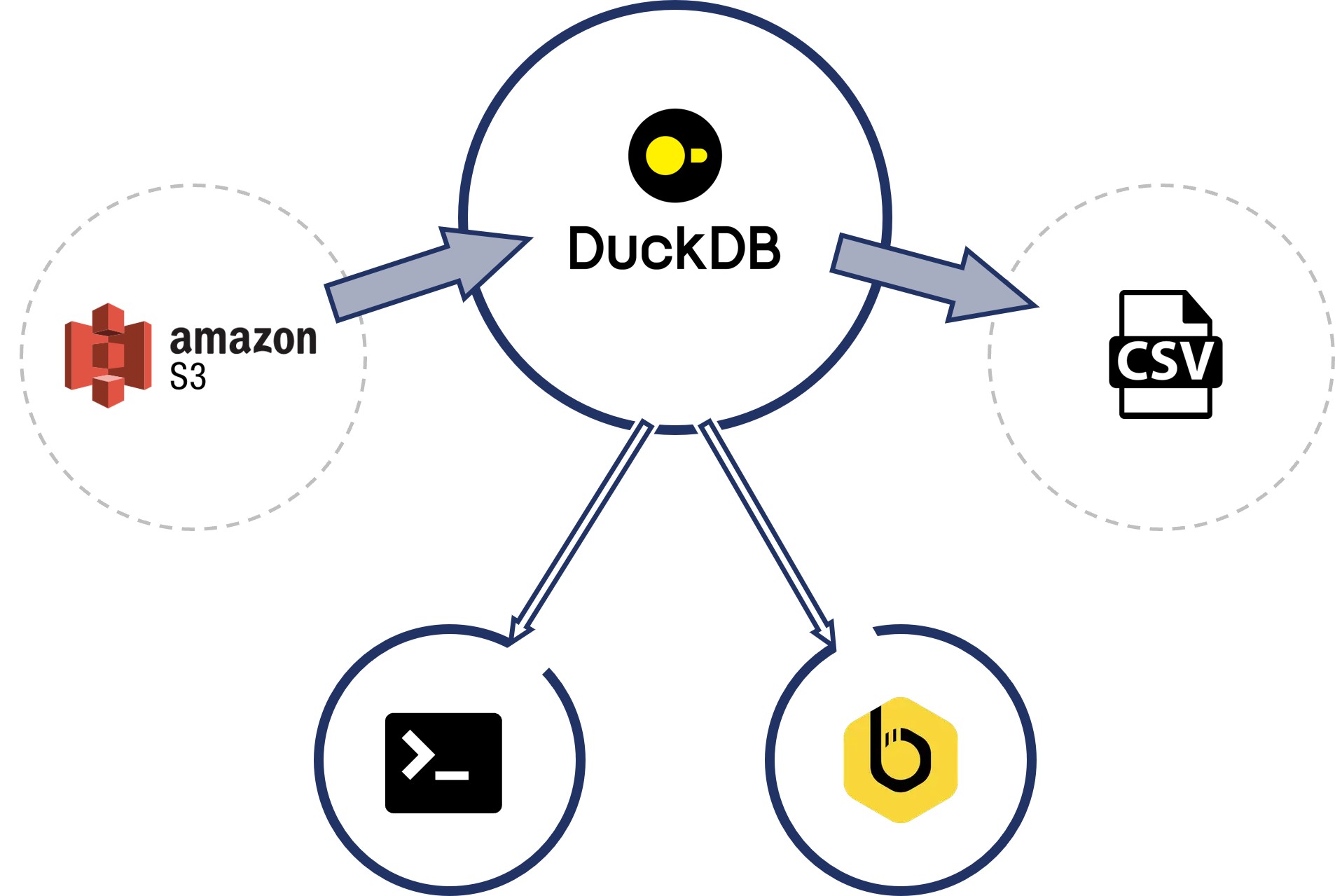
Une fois les fichiers CSV disponibles, l’équipe a pu lancer le pipeline existant sur les dates manquantes et ainsi intégrer les données historiques dans le datawarehouse.
Ceci montre l’utilisation de DuckDB en tant qu’outil de productivité pour une opération one-shot.
Conclusion
L’adoption de DuckDB est portée par les professionnels de la data qui préfèrent la versatilité, la simplicité d’usage, la performance, et un dialect SQL moderne. Son intégration dans la data stack bénéficie à tous les métiers de la data.
Pour aller plus loin, vous pouvez consulter la ressource suivante qui liste des entreprises ayant choisi DuckDB et décrit plus en détail l’intégration de l’outil dans leur infrastructure et leurs processus, https://motherduck.com/blog/15-companies-duckdb-in-prod/
En résumé, les points forts de DuckDB :
- Rapidité sans infrastructure lourde
- SQL puissant en environnement local
- Traitement analytique sur fichiers
- Intégration fluide avec les outils data